- A+

十多年前的1997年,由IBM研发的计算机“深蓝”战胜了当时的世界棋王卡斯帕罗夫,这场世纪性的”人机象棋对战”最终以人类败给计算机而落幕,开创了史上人工机械智慧战胜人脑智力的先河。人们在当时为这场别开生面的电脑博弈传奇感叹之际,也开始了对人工机械智能的深切担忧:机器会否最终超过人类,进而取代人类成为世界的口袋德州主宰?
如今,人机博弈机器胜的一幕再度上演。不过,这回,连我们曾经风流倜傥、拥有无数粉丝热爱的“赌神”也要坐不住了:人类在德州游戏领域也不再是最强者,在国际象棋领域之后,AI开始向新的人类高等智力游戏领域进军,开始问鼎德州游戏冠军的巅峰了!


Pluribus:再创人机博弈新纪元
近期,一款由CMU和Facebook联合研发的名叫“Pluribus”的AI扑克牌机器人在六人无限制德州游戏这项复杂游戏中,碾压了人类职业选手——这是AI机器人首次在规模超过两人的复杂对局中击败顶级人类玩家。与其他动辄上百万美元的AI突破性成果形成鲜明对比,Pluribus的蓝图策略在64核CPU的服务器上训练了8天,使用512 GB的RAM,没有使用GPU。在一般的云计算实例价格下,训练费用不到150美元!
许多网友们纷纷感慨:“原来小资源的研究也能推动人工智能研究大步向前发展”。这项研究让人们对如何构建通用的人工智能有了更好的基础理解。

横空出世的德扑AI,打遍天下无敌手
Pluribus是Facebook与卡内基梅隆大学合作开发的德州教学新型AI机器人,它成功实现了这一目标,击败了德州游戏精英人类玩家:比赛采用六人无限制德州游戏。Pluribus在“五个AI和一个人类玩家”和“一个AI 和五个人类玩家”的比赛中都击败了人类职业玩家。
在每个筹码价值1美元的假设下,Pluribus每手牌平均能赢5美元,在与五名职业玩家的对战中,每小时能赢 1000美元。可以说是取得了决定性胜利。
Pluribus是AI人机对战中的有一个全新里程碑,为什么呢?因为AI第一次突破了双人零和德扑简介博弈第一次表明了AI算法可以在双人零和博弈领域之外,达到超过人类的表现。
“不完全信息博弈”:
打破传统博弈论的桎梏
目前,很多超越人类的人工智能都是关于两人零和游戏,如围棋、以及“深蓝”所涉及的国际象棋:游戏中只能有一方可以获胜,用博弈论的术语来讲,这些人工智能所做的都是在找到一个接近纳什均衡的策略。所谓纳什均衡策略就是指一系列能够使自己预期收益最大化的策略,无论对手做什么行动,至少自己不会输,另一个博弈者也会采取同样的策略。

但是,Pluribus偏偏就是打破了传统博弈论最优策略的桎梏,探寻了一套独特的“自我博弈”策略:通过自我博弈计算出自己的策略。换句话说,Pluribus 不断跟自己的分身玩德州游戏,期间没有任何人类或其他人工智能的参与。最初,Pluribus 作为新手,行动完全随机,但它会不断改进自己的策略,逐渐提高自己的水平。自我训练得出的策略被称为“蓝图”。然后,Pluribus 就和真实玩家对战,积累实战经验,期间不断改进自己的策略。
据悉,Pluribus 采用了蒙特卡洛虚拟遗憾最小化算法(MCCFR)。MCCFR 会随机考虑一部分行动,而不是所有可选行动,来选择应该采取的决定。在MCCFR的每一次迭代中,人工智能会根据在场玩家的策略模拟一盘游戏,然后找出自己在模拟游戏中的最优策略。
“蓝图”策略只是一个粗略的策略。基于“蓝图”,Pluribus 在跟真正对手博弈的时候,用实时搜索(real-time search)技术寻找更好的策略。不同于围棋等完全信息博弈(perfect-information games),六人德扑俱乐部是不完全信息博弈(imperfect-information games)。
“会后悔”的AI,才是AI中的“战斗机”
智慧生命最大的特点就在于能够总结经验,并不断通过经验进行感知学习,从而得到进化和发展。由于纳什均衡的存在,使得之前的AI游戏机器人依然囿于“有限制对战”的范畴,因此过往的AI在三个或更多玩家参与的游戏中,纳什均衡而很难有效进行预期收益最大化计算,而纳什均衡也导致AI依然不是真正如同人类智慧一般有一个“尝试——学习——总结——进步”的过程存在,而仅仅做到了通过算法总结对手的特点和规律,避实就轻,被动地钻对方弱点的“空子”,从而达到了自己肯定不会输的一个结果。然而,在有两个以上玩家参与的德扑圈作弊中,即使在精确的纳什均衡策略下,有时也无法避免失败。
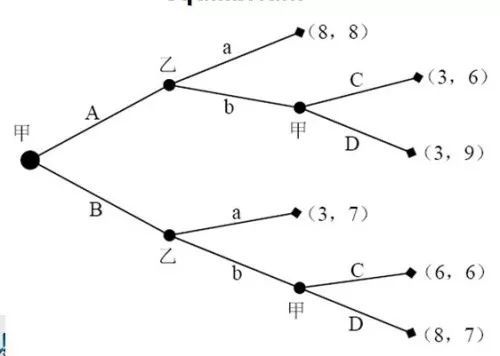
纳什均衡数学模型示意图
而Pluribus与以往的AI不同之处在于,在六人制非零和的德州游戏中,目标不应该是确定特定的博弈论解决方案的概念。为此,Pluribus独创了一种新的方法,他们假设每个玩家会有自己的4种策略,包括“蓝图”策略和它的三个变种,并且会在游戏中选择其中一种。由于对手会变换策略,Pluribus 就会计算出比较平衡的策略,而不会偏向于只采取某些决定。另外,为了防止被对手看穿自己的策略,Pluribus 会先计算如果手上的牌跟现在不一样时,会采取什么行动。
深度优先的逻辑形式为系统带来了反事实遗憾的“后悔点”
同时,Pluribus在每一回合中都会被加入一个虚拟遗憾值,使它会后悔上次没有用其他更好的策略,那么下一轮人工智能就会有倾向选择上次后悔没选的策略。就这样,Pluribus每局都在学习如何击败以前的自己,从而不断提高自己的水平。Pluribus 得出一个可以平衡各种情况的策略后才开始该回合的行动。这正是机器进行经验积累学习的过程,对于AI机器人来说,这通常被认为是“超人”的表现。
隐藏信息解读:
主动出击才是AI与人类拉进距离的本质性诀窍
与”深蓝“不同的是,Pluribus面对的扑克牌类游戏,是典型的”隐藏信息解读“类游戏。与所有信息都摆在棋盘上一目了然的棋类游戏不同的是,扑克牌游戏除了研究对手策略,还需要解读对手的牌面后所隐藏的未知信息。也就是说,AI和人类一样始终无法知道对方的牌是什么,要想在扑克中获胜,也需要bluff(虚张声势地吓唬)或者使用其他策略,这在棋类比赛中一般是不需要的。这是牌类游戏独特的乐趣所在,也是AI进军牌类游戏真人德扑圈有没有挂的最大阻碍,使得在扑克中应用人工智能变得非常困难,也是游戏中人类智慧与机器智慧最大的一个“分水岭”。
有人认为,多人扑克已经不是一种游戏,而更像一种需要多种技能的艺术表达,这种艺术需要我们能够有效甄别其他人的互动、肢体动作甚至微表情,更需要决胜者可以利用这些信息在这次博弈中取胜,简单来说,这是忽悠和防忽悠能力的对抗。而这种观察别人表情、虚张声势的能力是一般观念中认为任何机械智能永远无法拥有的最“人性化”的性能,一定需要直视对方的眼睛,声东击西让对方难辨真假。

图片来源:量子位
但是,Pluribus却具备了一种普通AI不具备的“颠覆性”性能,在这里,虚张声势的含义也可以被提升为一种基于算法和训练的能力,一种进阶版的谈判博弈能力。对手越多,需要处理博弈的隐藏信息越多。也就是说,我们的Pluribus不但可以总结出对手的规律和套路、反省自己之前打法的软肋,还会主动出击,通过德扑游戏规则对于隐藏信息的解读从而推断出对手的心理,开启了一种“人机心理战“的新人机互动形式。