- A+


小编前言:卡耐基梅隆大学Brown·Noam教授和他的PHD学生Sandholm·Tuomas研发的德扑游戏AI Libratus(中文名”冷扑大师“)2017年底横空出世,在业界横扫了各路pro,其研究论文在2018年成为该领域年度最佳论文,我们的锦标赛课程作者徐凌老师认真研读了论文,写下了此篇读后感。PokerLogic在2018年的最后一天与大家分享此篇文章,祝大家新年愉快。
德扑游戏被认为AI不可战胜人类
即使在Alpha Go战胜李世石之后,人们也认为短期内AI在德扑游戏上是不可能战胜人类的。因为国际象棋和围棋都属于完全信息游戏,双方都可以看到对方怎么排兵布阵然后选择自己的策略,而德扑游戏属于不完全信息游戏,游戏一方并不知道另一方拿着什么牌,也不知道对方采取的行动的动机是什么(是咋呼还是获取价值)。
德扑游戏游戏理论上是比围棋更复杂的游戏,因为德扑游戏每手牌有10的161次方种可能性,这比宇宙中的原子还要多。而围棋每局比赛有10的172次方种可能性。
之前最优秀的德州游戏规则AI对阵职业顶尖选手,AI每100手牌要输掉9.1个大盲注。这是非常悬殊的实力差距。
不过之前AI已经解决了罗德岛扑克(也就是手上只拿一张底牌的扑克,这游戏只有10亿种可能性,可以穷尽所有打法,所以容易解决),与限额下注德扑游戏(有10万亿种可能性)。

为什么德扑游戏AI开发很难
因为围棋这种完全信息游戏,之前的行动历史不会影响未来的决策。而德扑游戏是不完全信息游戏,在一手牌打到转牌(第三轮下注),AI还需要返回去“思考”对手之前行动可能代表有什么牌。打到河牌(最后一轮下注),还需要根据行动再返回去修改之前的判断。而每种行动有代表非常多的可能性,这会使得寻找当前的最优解法非常困难。
这种机制使得AI不能使用人工神经网络方法,而AlphaGo使用的人工神经网络已经有很多现成的德州教程方法与工具。德扑游戏AI一般使用最小后悔方法。
此外不同手牌之间历史也需要考虑,某个玩家连续做大咋呼,也许下一次更倾向于拿好牌做同样行动。或者玩家是否已经情绪失控了。(不过冷扑并没有考虑玩家每手牌之间的历史,对冷扑来说每手牌都是完全独立的。它不会知道选手之前是否在做陷阱或者已经情绪失控了)
冷扑VS职业选手
2017年1月。冷扑挑战4位世界顶尖人类德扑游戏单挑选手,他们每人在20天内与冷扑游戏了12万手牌。比赛结束时,冷扑一共赢了170万美元,平均每100手牌赢14.7个大盲。在同年4月卡内基梅隆大学校友李开复携冷扑,与由中国德州技巧高手组成的龙之队在海南比赛,冷扑再次获得巨大胜利。
冷扑的诀窍
冷扑的诀窍是:在每手牌,每一轮下注寻找纳什均衡打法,也就是我们俗称的GTO打法。通过自己严格按照纳什均衡打法游戏,其他玩家只要偏离了最优均衡打法,它就肯定会受到损失。数学证明在扑克单挑游戏中只要坚持纳什均衡打法,就能保证盈利(除非对手也按纳什均衡来打),所以冷扑并没有针对其他游戏玩家的风格来改变打法,它只是按自己节奏打。注意以上结论只适合于单挑游戏,不适合于多人桌游戏以及锦标赛。
以下内容如果对冷扑系统不敢兴趣可以选择跳过…
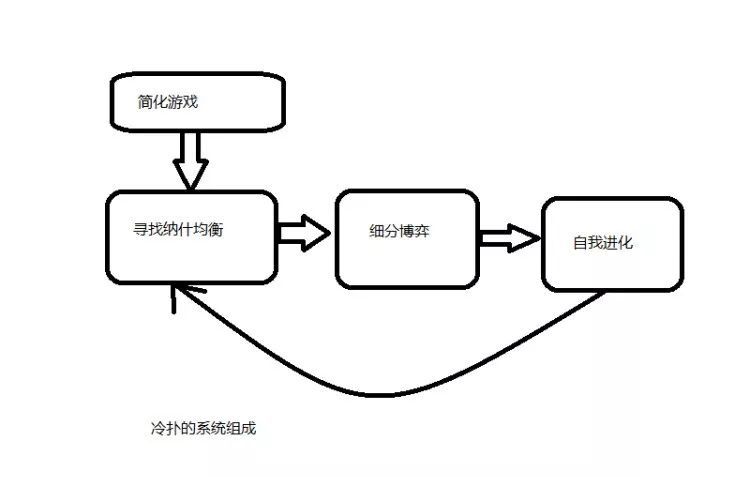
冷扑系统分为3大板块
1. 抽象化扑克游戏,也就是缩减扑克游戏复杂度。然后使用最小后悔算法寻找纳什均衡打法。
2. 细分博弈。 这个德州规则系统是为了寻找在计算出来的一堆博弈情景中,AI和玩家处于哪种博弈情景之中。
3. 自我进化。通过分析一整天的比赛数据与玩家的策略,寻找并修复自己的游戏漏洞,使得第二天比赛更完美。