- A+

针对德州扑克AI的对手建模与策略集成框架
引用本文
张蒙, 李凯, 吴哲, 臧一凡, 徐航, 兴军亮. 一种针对德州扑克AI的对手建模与策略集成框架. 自动化学报, 2022, 48(4): 1018−1031 doi: 10.16383/j.aas.c210127
Zhang Meng, Li Kai, Wu Zhe, Zang Yi-Fan, Xu Hang, Xing Jun-Liang. An opponent modeling and strategy integration framework for Texas Hold’em. Acta Automatica Sinica, 2022, 48(4): 1018−1031 doi: 10.16383/j.aas.c210127
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c210127?viewType=HTML

文章简介
关键词
不完美信息博弈, 德州扑克, 演化学习, 在线对手建模, 种群策略集成
摘 要
以德州扑克游戏为代表的大规模不完美信息博弈是现实世界中常见的一种博弈类型. 现有以求解纳什均衡策略为目标的主流德州扑克求解算法存在依赖博弈树模型、算力消耗大、策略过于保守等问题, 导致智能体在面对不同对手时无法最大化自身收益. 为解决上述问题, 提出一种轻量高效且能快速适应对手策略变化进而剥削对手的不完美信息博弈求解框架. 本框架分为智能体离线训练和在线博弈两个阶段. 第1阶段基于演化学习思想训练智能体, 得到能够剥削不同博弈风格对手的策略神经网络. 在第2博弈阶段中, 智能体在线建模并适应未知风格对手, 利用种群策略集成的方法最大化剥削对手. 在两人无限注德州扑克环境中的实验结果表明, 本框架在面对动态对手策略时, 相比已有方法能够大幅提升博弈性能.
引 言
计算机博弈与人工智能的发展一直相辅相成. 自人工智能(Artificial intelligence, AI)学科诞生伊始, 计算机博弈研究就是AI技术发展创新的沃土, AI领域的先驱图灵和香农都曾研发过计算机博弈程序. 用于测试机器是否具有“智能”的图灵测试, 其实现形式就是通过人和机器之间博弈进行的. 智能博弈一直都是衡量AI技术发展水平的重要评价准则, AI发展历史上的主要里程碑事件都与计算机智能博弈游戏研究相关. 1962年6月机器学习之父阿瑟·塞缪尔的西洋跳棋程序战胜美国著名职业选手尼雷、1997年5月IBM公司的超级电脑“深蓝”战胜国际象棋大师卡斯帕罗夫等,都是AI学科早期发展历史上重要的里程碑事件.
近年来, 计算机的存储与计算能力不断提升, 以及各类数据的爆炸式增长与积累, 以人工神经网络为主要技术工具的深度学习方法, 因其强大的数据拟合能力与泛化能力, 使其在语音识别、图像识别和自然语言处理等领域都取得了突破性进展, 成功推进了AI领域由感知智能到认知智能的跨越. 如今, AI领域正在经历从认知智能迈向决策智能的过程, 以强化学习与深度学习相结合的深度强化学习方法, 在围棋博弈领域取得了重大突破并成功打败人类顶尖选手, 为完美信息场景下的博弈决策问题提供了有效的方法指导. 而智能体如何在其所处状态信息不完全已知的情况下做出准确的决策, 是目前AI领域面临的核心问题. 因此, 不完美信息博弈场景下智能决策问题的研究和解决, 是AI取得突破的核心前沿领域和重要驱动力.
游戏是一种虚拟的实验环境, 具有可控损失的优点, 实验成本低且允许实验失败. 博弈游戏本身又存在很多难点, 具有决策空间复杂、实时高动态、信息不完美等特点, 能够为智能决策问题研究提供一种良好的算法实验环境, 是AI技术绝佳的实验研究平台. 不完美信息博弈游戏是指智能体在游戏中只能够获得自身的游戏状态以及公共游戏信息, 而无法掌握全部的局面信息, 例如在德州扑克、麻将、斗地主等游戏博弈过程中对手的手牌不可见, 因此获得的局面信息是不完美的, 这也使此类博弈游戏的研究和解决更具挑战性.
现实生活中, 在军事、经济、商业、网络安全等实际场景中的大多问题, 均属于不完美信息博弈问题. 此类问题的研究和解决往往受到实际环境的成本制约, 而将其转化为对博弈游戏抽象模型的求解寻优问题可以大幅降低所需实验成本. 因此, 以不完美信息博弈游戏为载体的研究, 能够为现实问题的解决提供有效的方法论.
本文选择德州扑克游戏作为对不完美信息博弈的主要研究和实验对象, 以演化学习方法和深度神经网络相结合完成对智能体的训练, 通过在线的对手风格建模和种群策略集成的方法使智能体能够适应对手策略变化, 最终实现一种轻量高效并对解决不完美信息博弈问题具有通用性的博弈求解框架.
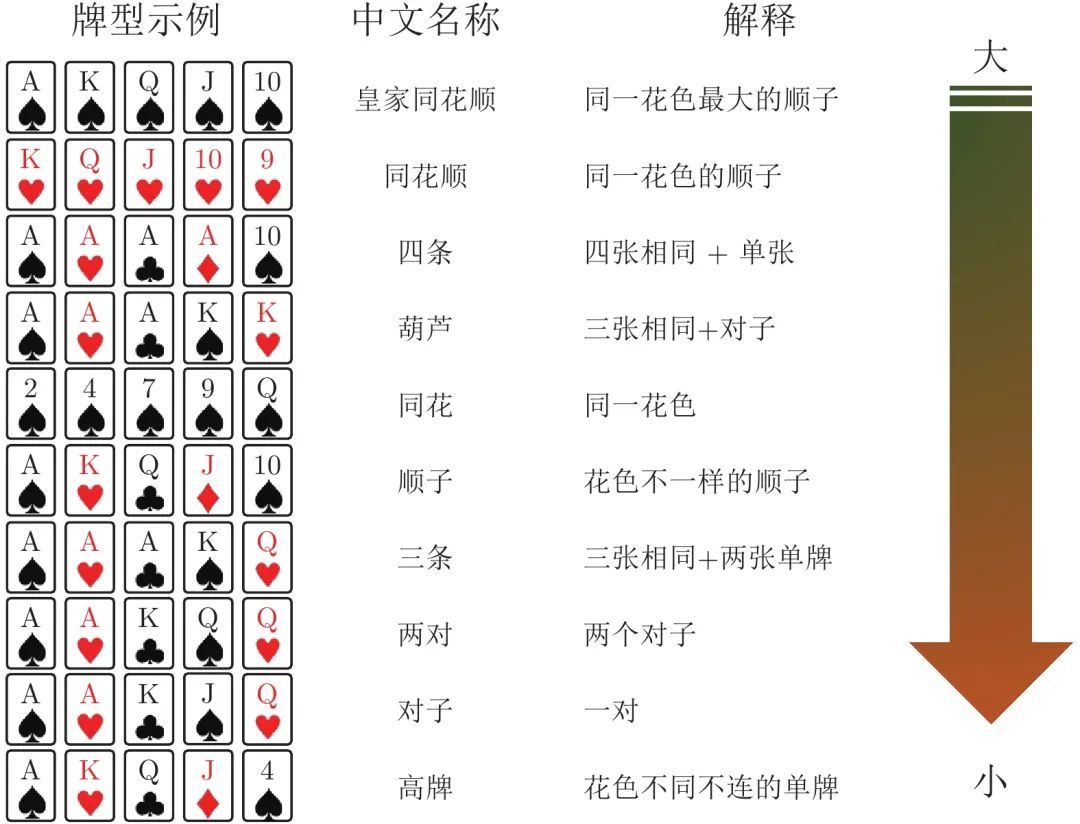
图 1 德州扑克游戏牌型大小规则

图 3 对手池策略空间与博弈风格类型定义
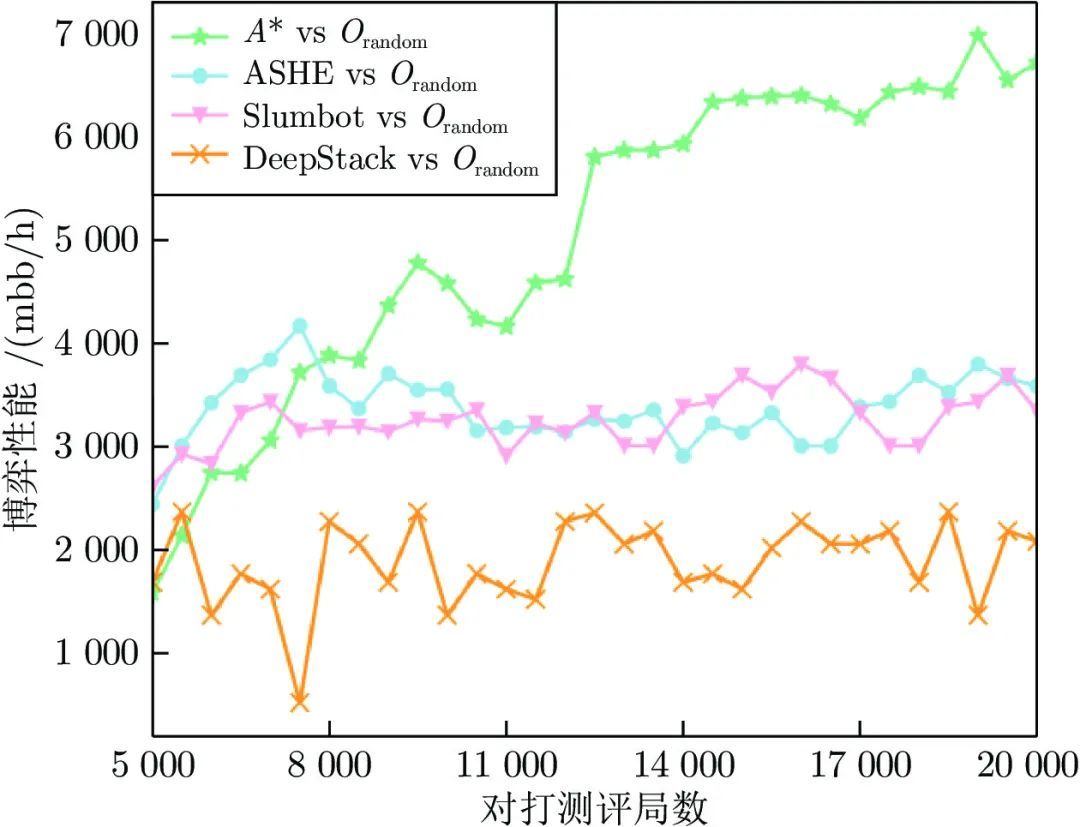
图 11 对打测评过程中博弈性能变化
作者简介