- A+


德扑AI大神、AAAI学术新星 Noam Brown:不完美信息多智能体场景下的AI研究


图 1:用于不完美信息多智能体场景下的人工智能
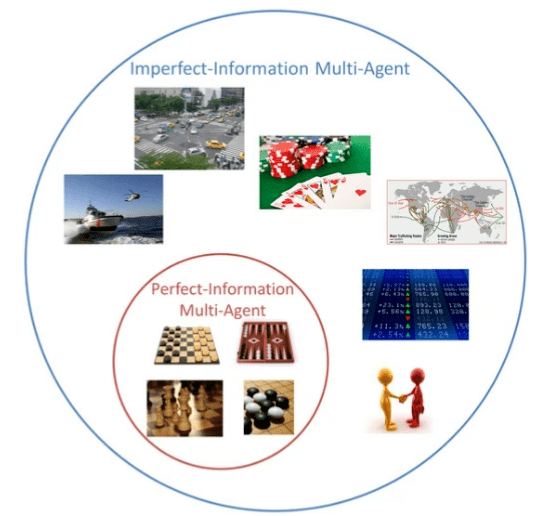
图 2:不完美信息多智能体
Noam Brown,卡耐基梅隆大学(CMU)博士,Facebook 人工智能实验室研究科学家、AI德州扑克作者,致力于使AI在大型不完全信息多智能体交互中进行战略推理。
引言
首先,本文提及的「多智能体环境」也被称为「博弈」,它指的是涉及多个参与者可以完成的行为,以及根据选定的行为得到的收益的任意形式的策略交互。
早在人工智能领域兴起之初,多智能体环境就成为了一种极具挑战的问题,并且成为了人工智能研究的一类对比基准。举例而言,国际象棋在很长一段时间以来都是一种很困难的人工智能问题,该领域的大多数研究工作都重点关注「完美信息博弈」,此时博弈参与者知道所处世界的确切状态。
另一方面,我的研究倾向于关注不完美信息博弈。在这种博弈中,玩家可以获得其他玩家无法获得的私人信息。如果我们想要在现实世界中部署人工智能系统,我们必须能够解决这类隐藏信息的问题,因为大多数现实世界的策略交互都涉及到一些隐藏信息。例如,金融市场、安全交互、业务谈判,甚至车辆导航场景下都涉及隐藏信息。

图 3:无限制德州扑克
长期以来,扑克都是博弈论领域中的一项极具挑战性的问题。具体而言,「无限制德州扑克」是其中的一种变体。实际上,早在上世纪 40、50 年代,博弈论领域就有人撰写论文来研究扑克。而扑克也是一种大规模博弈,在「无限制德州扑克」中,博弈双方拥有 10^161 个决策点。到目前为止,「无限制德州扑克」是世界上最流行的一种扑克游戏。在各种有关扑克的电影(如图 3 所示的电影《007 大战皇家娱乐场》)中都有「无限制德州扑克」的身影。每年的扑克世界巡回锦标赛也都会举办有关「无限制德州扑克」的比赛。

图 4:2017 年的人机扑克大战——Libratus
在很长一段时间内,人工智能系统都无法击败世界上顶尖的扑克选手。直到 2017 年,我和我的导师研制出了 Libratus,它与世界上 4 位最顶尖的「无限制德州扑克」对战,并成功击败了他们。在 2017 年 1 月的 20 天内,Libratus 打了 120,000 手扑克。最终超过 20 万美元的奖金池根据选手的表现分给了扑克高手们。Libratus 以极大的统计显著性(大约正态分布周围 4 个标准差)获得了胜利,每一位选手都败给了 Libratus。

图 4:2019 年的 Pluribus 实验
继 Libratus 之后,我们在 2019 年推出了 Pluribus 人工智能系统,它与 15 名世界顶尖的扑克专家进行 6 人无限制德州扑克游戏。Pluribus 在 12 天中打了一万手德州扑克,它使用了方差缩减技术来降低运气成分。同样,Pluribus 也以极大的统计显著性获胜。值得一提的是,尽管我们将 Libratus 的双人博弈扩展到了 Pluribus 中的六人博弈,指数级地扩大了博弈的规模,但是 Pluribus 的训练开销却比 Librabus 小得多,我们只需要花费不到 150 美元,在 28 个 CPU 核上就可以训练 Pluribus(无需 GPU)。
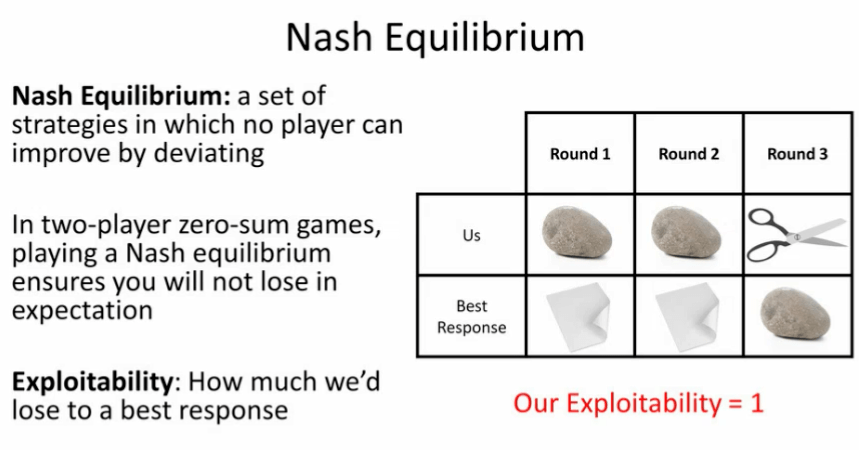
图 5:纳什均衡与可利用性——石头、剪刀、布
2
Librabus和Pluribus的博弈论方法
接下来,我们将简要介绍 Librabus 和 Pluribus 中用到的博弈论方法。
首先,纳什均衡指的是在某组策略下形成的一种局面:没有人能够通过改变自己的策略改善自己的收益。在二元零和博弈中,形成纳什均衡可以保证无论我们的对手如何行动,从期望上说,我们都不会输掉。此外,可利用性(exploitability)指的是:我们的结局比最佳对策差多少(即如果对手完美地反击了我们,从期望上说,我们将会输多少)。
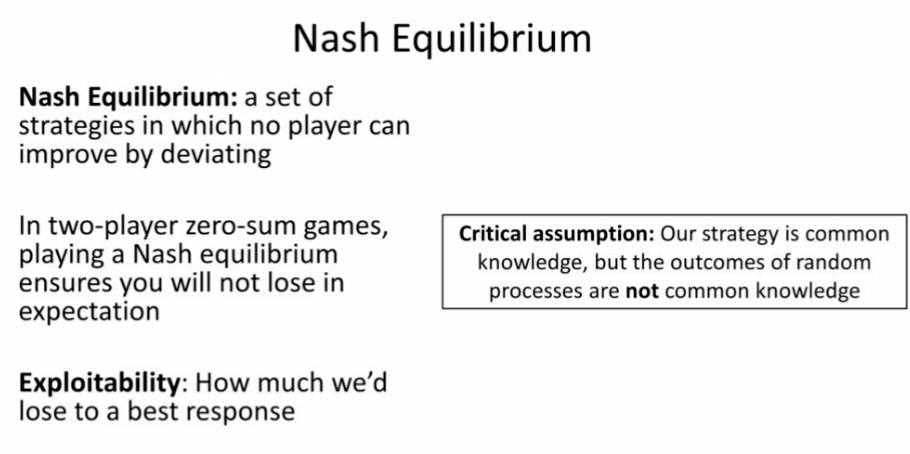
图 6:关键假设
如果我们真的想要部署一个数以亿级的用户都会使用的人工智能系统,我们需要保证他们无法「利用」我们。为此,我们假设对手知道我们的策略,而并不知道随机过程的结果。因此,我们希望即使他们知道我们的策略,我们的策略仍然应该鲁棒(这是博弈论中的一个普遍的假设)。我认为这个研究动机是成立的,因为如果用户有充足的时间与我们的系统进行交互,他们最终会想到我们的策略是什么,并想出相应的对策。这样一来,我们首先应该试图最小化系统的可利用性。
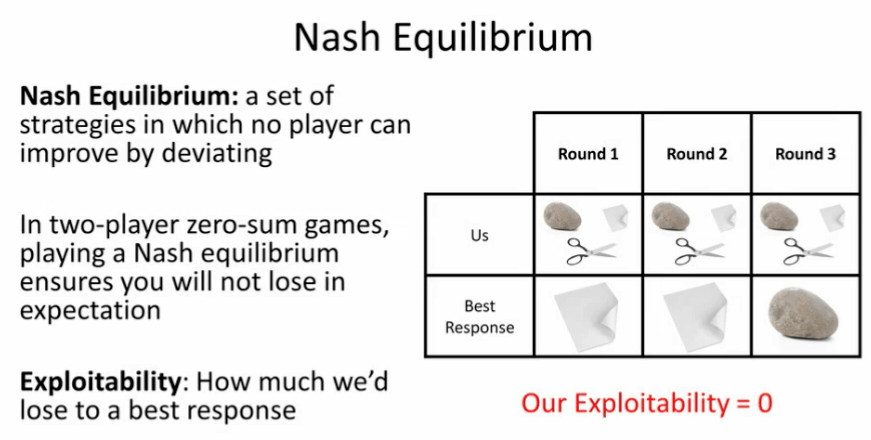
图 7:通过随机化方法改进「石头、剪刀、布」中的策略。
在「石头、剪刀、布」游戏中,我们可以通过随机化方法实现上述目标。如果我们在出石头、布和剪刀之间随机分配相同的概率。那么不管对手怎么做,他们都无法做出最佳的对策。也就是说,他们无法「利用」我们,此时便达到了纳什均衡。
在这种情况下,你可能会认为,从期望上说我们并不会输,不会被「利用」。但是,在形成纳什均衡的局面后,我们也不会赢。在「石头、剪刀、布」游戏中,这种想法是成立的。
但是当问题扩展到越来越大的博弈场景下,想到如何做出最好地应对以达到纳什均衡会越来越困难。在对手试图做出最佳对策时,他们很有可能会出错。如果我们达到了纳什均衡,从期望上说,我们不会输掉。但是实际上,我们需要最终胜出。
有人说:打扑克其实很简单,只要对手犯错,我们就可以从中获利。这也正是我们在扑克游戏中采用的方法,许多专业扑克选手也向我们推荐了这种方法。
接下来,我们将讨论非二元零和博弈中的均衡。此时,我们无法在多项式时间内计算出纳什均衡。即使我们可以高效地计算出纳什均衡,这么做也没有意义。这是因为在非二元零和博弈中,一些纳什均衡的优秀性质(例如,从期望上说,我们不会输掉)就不复存在了。然而,本次演讲中提到的算法在这种情况下效果仍然很好。这些算法在实际情况下通用性如何仍然是个有待研究的问题。

图 8:非二元零和博弈中的均衡
反事实遗憾最小化
接下来,我们将介绍在大型博弈中计算上述均衡的一种方法:反事实遗憾最小化。在本次演讲中,我们将介绍该算法的蒙特卡洛版本。
CRF 是一种迭代式的算法,它会逐渐收敛到纳什均衡。同时,CRF 是一种自我博弈(self-play)算法,智能体会与自己进行对局。在起始状态下,该智能体会完全随机地进行博弈。随着时间的推移,智能体会学习到效果好的动作和效果不佳的动作。它会更多地采用在过去的所有迭代过程中效果良好的动作。最终,CRF 算法会收敛到一种纳什均衡状态。
如图 9 所示,我们将遍历玩家 1(P1)的博弈树,在下一轮迭代中我们将转而考虑玩家 2,接着再考虑玩家 1......如此循环往复。玩家会一直在每个决策点上为博弈中的每个动作维护一个被称为遗憾值(regret value)的指标。在每次需要做出动作时,玩家会选择动作的概率与正向遗憾值成正比。遗憾(regret)值对应于玩家有多么后悔在之前的情况下没有采取某个动作。在第一轮中,所有的遗憾值都为 0。
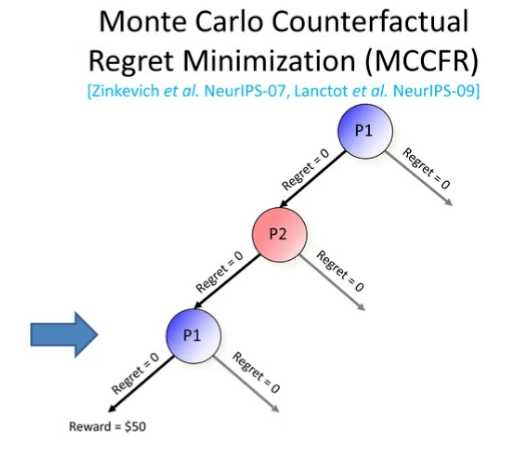
图 9:第一轮 MCCFR 博弈树
第一轮迭代过程如下:
Step 1:在博弈开始时,我们考虑的是玩家 1。请注意,玩家 1 选择动作的概率正比于正向遗憾值。此时所有的遗憾值为 0,这意味着他们会均匀、随机地选取动作。假设他们随机地选取了左侧的分支,我们会来到玩家 2 的决策点。
Step 2:同样地,玩家 2 选择各种动作的概率也与其正向遗憾值成正比。假设玩家 2 随机选择了左侧分支。接着,我们又回来到另一个玩家 1 的决策点。
Step 3:假设此时玩家 1 又随机选择了左侧的分支,我们最终得到了 50 美元的奖励。
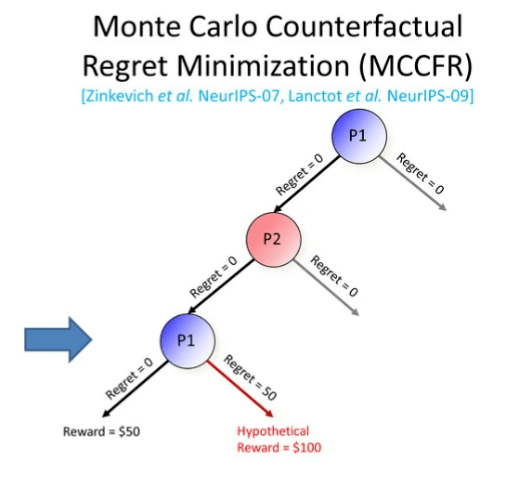
图 10:计算右侧动作的遗憾值
现在,玩家 1 将会审视他们本来可以采取(但没有采取)的所有其它动作。例如,他们在 Step 3 中本可以采取右侧分支的行动,并且得到 100 美金的奖励。此时,该动作的遗憾值就上升了。通过他们在反事实情况下选取右侧动作本可以得到的奖励减去他们实际选取左侧动作得到的奖励,我们计算出此处的遗憾值上升了 50。在未来的情况下,由于右侧动作的遗憾值更高,所以玩家选取该动作的概率就会更高,。
实际上,这与人类学习玩游戏的方式非常相似。举例而言,在打扑克时,我们往往会问「假如我当时采取了其它的动作,对手会作何反应呢」?这种假设推理与 CRF 算法中的智能体的思考方式是类似的。由于智能体此时与自己对弈,因此能够计算出某种假设的奖励是多少。在如图 10 所示的过程中,他们可以看到在怎样的情况下会获得 100 美元的奖励。
在更新了遗憾值后,算法会向上传递他们实际获得的 50 美元的奖励。由于我们只更新本轮迭代中玩家 1 的遗憾值,所以我们会跳过所有玩家 2 的决策点。同样地,玩家 1 会探索所有他本来可以才去的行动。玩家 1 本来可以在根节点选择右侧的动作。然后他们会达到另一个玩家 1 节点,假设此时它们选择左侧分支并且获得了 -500 美元的奖励。此时,他们继续探索他们本可以采取的行动(选择右侧的分支)。如果他们选择了右侧的分支,他们将得到 100 美元的奖励。此时右侧动作的遗憾值上升为 600 ,而根节点对右侧动作的遗憾值变为了 -550。
在本轮迭代完成后,我们会以同样的方式更新玩家 2 的遗憾值,接着再重新更新玩家 1,玩家 1 会以更高的概率选取遗憾值更高的动作......如此循环往复。
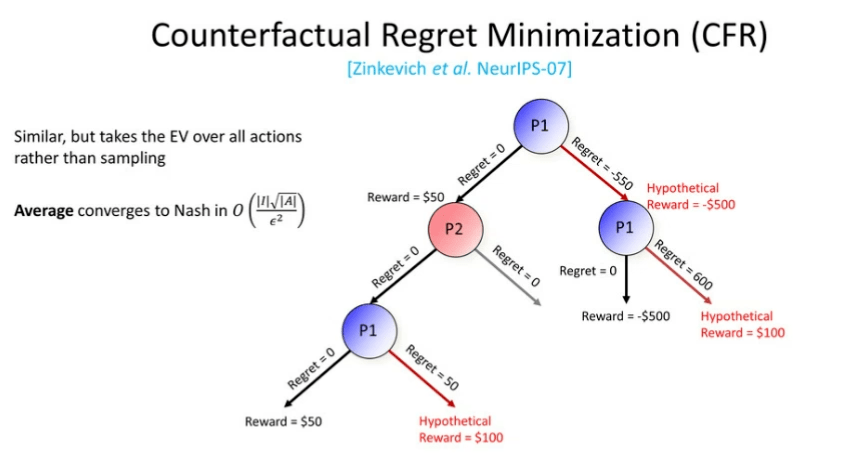
图 11:反事实遗憾最小化
至此,我们介绍了 CFR 算法的蒙特卡洛版本。而 CFR 算法的非蒙特卡洛版本工作原理与前者相类似,只不过我们需要对所有的动作取期望值,而不是对它们进行采样。在所有迭代后得到的平均值将会收敛到纳什均衡。
4
CFR的变体
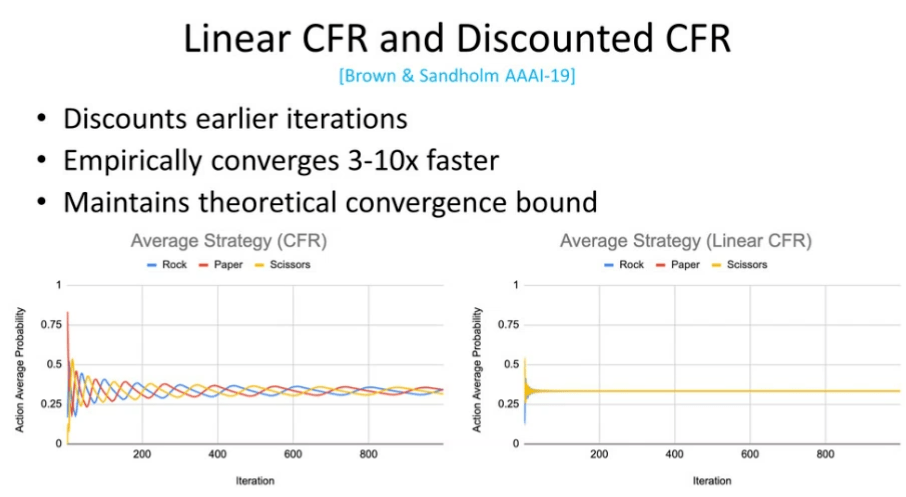
图 12:线性 CFR 和折扣化 CFR
如今,CFR 算法已经成为了计算大规模不完美信息博弈中的均衡的常用方法。但是,CFR 真正的强大之处在于近年来出现了许多对其进行改进的变体。原始的 CFR 方法在计算纳什均衡时效率很低。我们接下来将介绍的两种 CFR 变体则十分高效,它们是目前许多大规模不完美信息博弈场景下性能最佳的方法。
线性 CFR 和折扣化 CFR 背后的思想是降低较早的迭代的影响,这样可以维持 CFR理论上的收敛界(尽管实际上收敛的要快一些)。以图 12 左侧为例,我们给出了「石头、剪刀、布」游戏中的收敛情况。可以看出,CFR 策略给出石头、剪刀、布的概率会逐渐收敛到 1/3。在图 12 的右侧,我们可以通过线性 CFR 算法实现相同的效果,但是其收敛速度则要快得多。
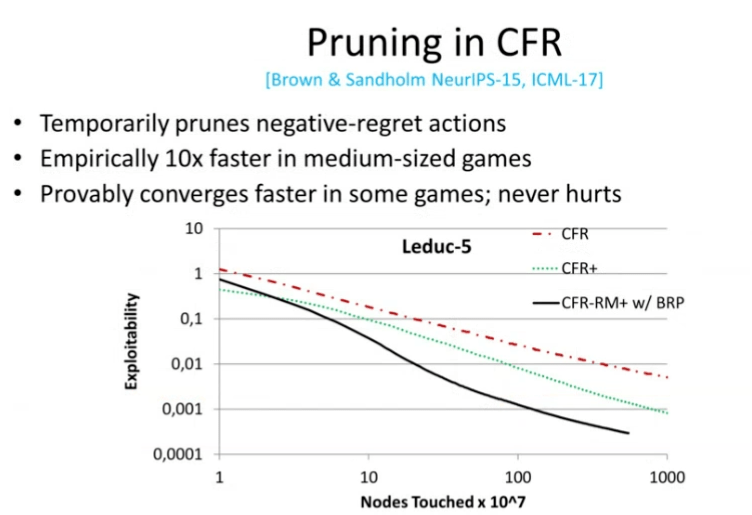
图 13:CFR 的剪枝策略
另一方面,我们关注 CFR 的剪枝策略。剪枝背后的思想是,我们没有必要在每一轮迭代中探索那些遗憾值为负且其绝对值很大的动作。我们至少可以暂时将它们剪枝掉。从理论上说,我们是可以实现这种剪枝策略的,并且不会损害模型的性能。在多种博弈场景下,我们的剪枝策略最终很可能加速模型收敛。实验结果表明,我们在中型规模的博弈中取得了 10 倍的加速。
如图 13 所示,在中型扑克游戏 Leduc-5 中,y 轴代表可利用性(我们距离纳什均衡有多远),我们希望可利用性的值下降。另一方面,x 轴代表我们已经考虑过的决策点。红色的虚线代表原始版本的 CFR,绿色虚线代表 CFR 的一个改进版(CFR +),黑色的实线代表使用了基于遗憾值的剪枝策略的 CFR。可以看到,我们改进后的算法将收敛速度提升了一个数量级。
基于深度学习的CFR/DREAM算法
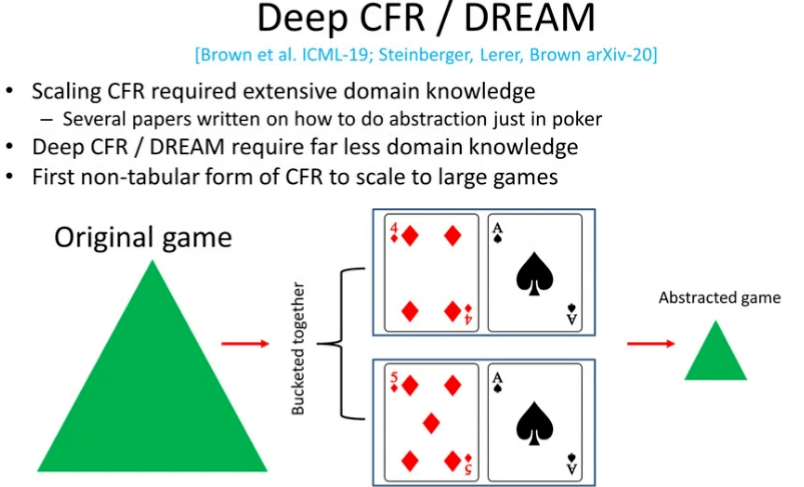
图 14:基于深度学习的 CFR/DREAM
基于深度学习的 CFR(Deep CFR)/DREAM 算法是另一个令人激动的领域。它们是 CFR 的非扁平版本。为了将原始的 CFR 算法扩展到超大规模的博弈(如「无限制德州扑克」)中,我们需要使用一种名为「抽象」的技术。「抽象」背后的思想是,在博弈中将多个相似决策点合并起来同等地处理,而不是在每个决策点上考虑每个动作的遗憾值。例如,扑克中的两种同花顺「queen high flush」和「king high flush」将会拥有各自而定遗憾值,而在使用「抽象」技术后,我们会将二者放在一起同等地处理。因此,在使用了「抽象」技术之后,我们可以将合并起来的决策点一同更新,而不需要分别更新这些不同情况下的决策点。「抽象」技术对于扑克游戏十分有效。而想要将该技术拓展到其它领域也很困难。实际上,已经有许多研究者撰文讨论如何在扑克领域进行「抽象」。
基于深度学习的 CFR/DREAM 算法真正的强大之处在于,它使我们可以在需要的知识少得多的情况下,达到相似的性能。实际上,基于深度学习的 CFR 是首个将 CFR 应用到大型博弈中的非扁平 CFR 形式。而 DREAM 是一项后继的工作,它实现了与「Deep CFR」相近的性能,并且它是模型无关的,即我们无需知道交互的规则。这意味着,Deep CFR 和 DREAM 算法提供了将 CFR 拓展到极为复杂的多智能体环境(甚至是三维环境)下的途径。目前,将这一算法拓展到连续动作空间中的三维环境下仍然是极具挑战的问题。但是我坚信我们目前的研究思路是正确的,未来对该算法的改进会使其更加强大。
5
实时搜索更好的策略

图 15:实时搜索更好的策略
「搜索」指的是,我们并不是立刻就采取动作,而是在底层花费大约 30 秒左右的时间基于某种算法决定出最佳的动作。
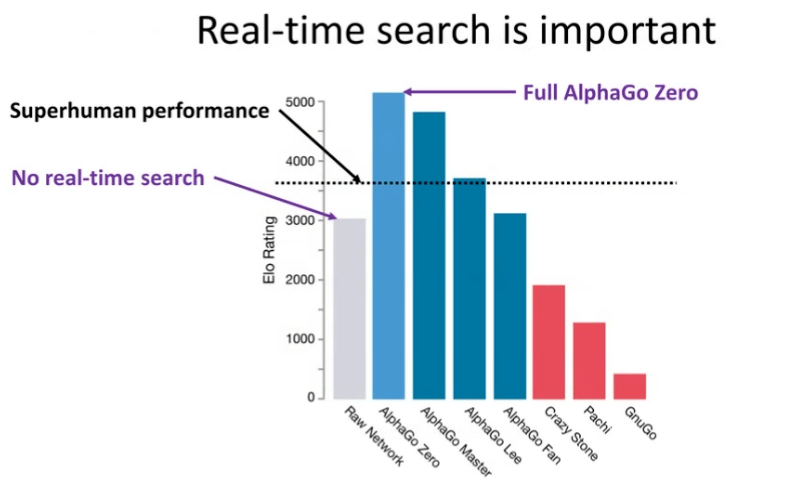
图 16:实时搜索是非常重要的
首先,搜索不仅仅对于非完美信息博弈十分重要,对于完美信息博弈也是如此。在图 16 中,y 轴代表了 Elo 等级分,它衡量了人类棋手和机器的表现。在围棋中,表现为「superhuman」的阈值被设定为 3,600 Elo。如图 16 所示,浅蓝色的竖线代表 AlphaGo Zero 的性能,显然其性能达到了「superhuman」水平。但是,如果我们去除掉测试时(甚至不用取出训练时)使用的实时搜索技术(本例中为蒙特卡洛树搜索),该系统的性能将会下降至灰色竖线所示的情况(大约 3000 Elo 等级分),而这并没有达到「superhuman」水平。这说明搜索对于围棋游戏是十分重要的。实际上,搜索的重要性不仅仅局限于围棋,它几乎对所有的游戏(例如,国际象棋、扑克)都很重要。
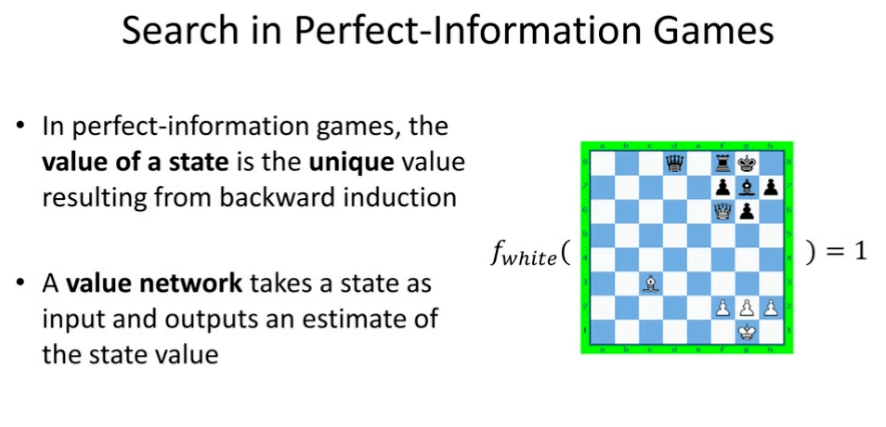
图 17:完美信息博弈中的搜索
不完美信息博弈中的搜索比完美信息博弈中的搜索要困难得多。为了解释这一点,我们首先将介绍搜索在完美信息博弈中的工作原理,其中「值函数」是核心的概念。在完美信息博弈中,某个状态的值是反向归纳得到的唯一值。而值网络则以某个状态作为输入,并且输出对于状态值的估计。如图 17 所示,在国际象棋棋盘中,如果白方用其皇后吃掉黑方的象,然后就会「将军」,此时白方该状态的值为「1」。因此,如果我们将此时棋盘的状态赋到值函数中作为输入,值函数会返回白方的值为「1」。

图 18:为什么非完全信息博弈中的搜索更加困难?
非完全信息博弈中的搜索更加困难,这是因为在非完美信息博弈中,并没有像在完美信息博弈中那样为传统的「状态」很好地定义「值」,这会导致现有的搜索技术失效。
石头、剪刀、布+
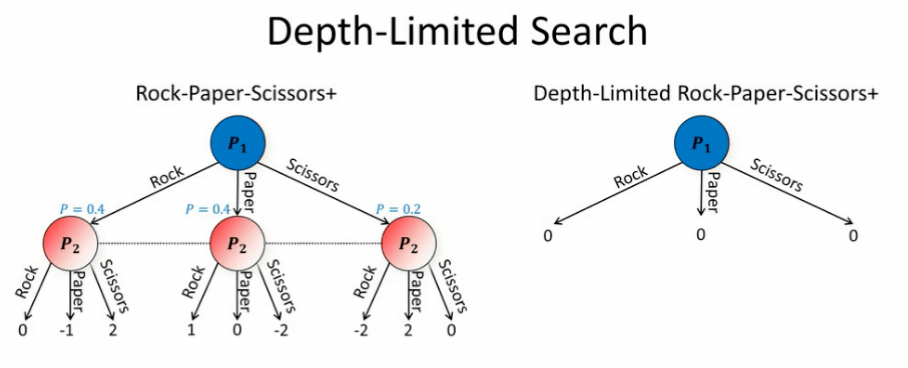
图 19:升级版的「石头、剪刀、布」
我们将以一个升级版的「石头、剪刀、布」(石头、剪刀、布+)为例说明非完全信息博弈中的搜索有多困难。除了「如果有选手出剪刀,那么获胜者会得到两分,败者则减两分」这一修改之外,该游戏的规则与「石头、剪刀、布」相同。而这一修改打破了原本游戏的对称性。
如图 19 所示,我们将给出该游戏中可能出现的序列化的情况。其中玩家 1 首先出招,接着玩家 2 在不看玩家 1 的出招情况的条件下也出招。在该游戏中,最佳的策略(纳什均衡)是以 40% 的概率出石头和布,而以 20% 的概率出剪刀。如果博弈双方都采取这种策略,那么值的期望就是 0。假设你是玩家 1,并且进行深度受限搜索,你会在某一步停下来,替换纳什均衡双方的值,然后再往下进行游戏。
在深度受限搜索情况下,玩家 1 会在石头、剪刀、布之间做出选择。接着,我们停留在这一步,将纳什均衡情况的值(0)输入给函数。接下来,我们需要对这个博弈进行求解。然而,此时我们并没有足够的信息让玩家 1 达到纳什均衡(以 40% 的概率出石头和布,而以 20% 的概率出剪刀)。最终可能会以 1/3 的概率均匀选取三种动作。
此时,问题在于我们假设无论玩家 1 做了什么,玩家 2 都达到纳什均衡。在完美信息博弈中,这种假设是成立的,但是在非完美信息博弈中并非如此。在非完美信息博弈中,动作的值依赖于该动作被选取的概率。例如,如果玩家 1 以 80% 的概率出石头,那么石头的值就会变化,因为玩家 2 会在玩家 1 出石头之后停下来,而这会打破纳什均衡。相反,他会常常出布。那么石头的值就会从 0 降为 -1。这就是非完美信息博弈和完美信息博弈之间的主要差别之一。
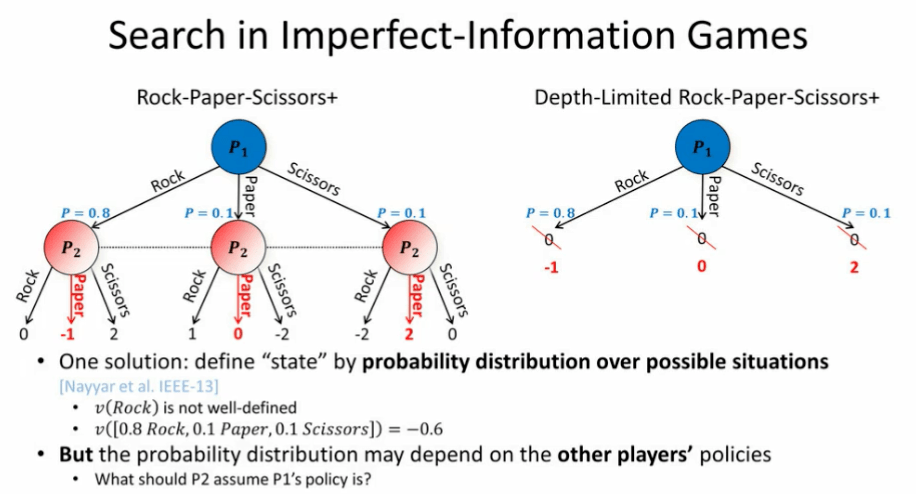
图 20:非完美信息博弈中的搜索
那么,我们如何处理这种差异呢?Nayyar 等人于 2013 年提出了其中一种解决方案。我们可以根据可能的情况的概率分布定义一种「状态」。其中,石头的值并没有被很好地定义。然而,「玩家 1 以 80% 的概率出石头、10% 的概率出剪刀、10% 的概率出布」这种情况的值被定义为 -0.6。这与「信念状态」和「部分可观测马尔科夫决策过程」的想法相似,只不过它被扩展到了多智能体环境下。这种思路被称为「公开信念状态」,其中我们可以将状态定义为所有玩家的不同可能性的概率分布。这一思路最早是为完全协作环境开发的。
然而,在非完全协作环境下(例如,对抗性环境、混合协作环境、竞争环境下),我们不再能够确定其它玩家的策略,这是因为他们可能会欺骗我们。如果我们不知道他们的策略,也就不知道我们所处的状态。对于玩家 2 来说,他应该设想玩家 1 的策略是怎样的,从而弄清他们所处的公开信念状态。那么,为了决定状态的概率分布,我们应该怎样假设对手们的策略呢?直观地想,我们可能会认为只需直接假设其他玩家处于纳什均衡状态,但是这样做并不可行。
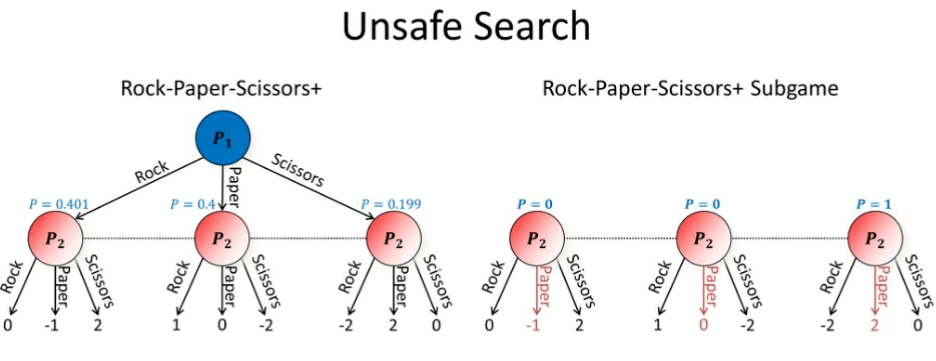
图 21:不保险的搜索
如图 21 所示,假设你是游戏中的玩家 2,现在轮到你做出动作。此时,你希望进行搜索。现在的问题是,你应该怎样假设玩家 1 之前的行为?一种看似合理的假设是:假设玩家 1 达到了纳什均衡。然而,这样做并不可行。
为了更简单地说明该问题,我们假设逼近了纳什均衡,但是并没有完美地达到纳什均衡。我们实现了玩家 1 的近似纳什均衡,他有 40.1% 的概率出石头,有 19.9% 的概率出剪刀,40% 的概率出布。现在轮到我们(玩家 2)出招。此时,我们的最优策略为以 100% 的概率出布。但是问题是,如果我们这么做,我们的对手在知晓了我们的算法后,可以通过从纳什均衡状态转变为总是出剪刀来对抗我们。这会使我们得到 -2 的值。因此,假设对手处于纳什均衡是一种「不保险」的搜索策略,因为对手可以利用我们这种假设。
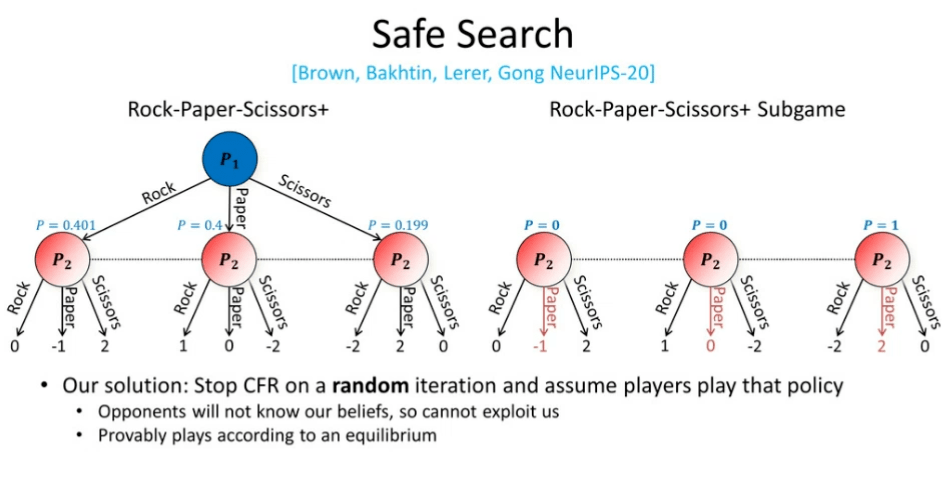
图 22:保险的搜索
为了解决上述问题,研究人员撰写了许多论文探究解决方案。但是我们最近于 NeurIPS 2020 上发表的方法是目前最有效的技术,它对我们所处状态的信念进行了随机化处理。其中,我们通过 CFR 算法判断对手的策略,而不是假设对手处于纳什均衡。此外,我们经过随机轮次的迭代后会终止算法,而不是将算法迭代固定数量的轮次。我们假设玩家的策略来源于这种随机迭代的过程,由于我们从一个随机的迭代过程中采样,对手就无法知道我们怎样对它们的策略进行假设,他们就无法利用我们的信念。根据纳什均衡,我们证明了这种有关信念的假设在理论上是合理的。
比纯粹的对抗和纯粹的合作更复杂的情况

图 23:比纯粹的对抗和合作更复杂的情况
最后,我们将讨论比纯粹的对抗和纯粹的合作更复杂的情况。在现实生活中,往往并不存在这种零和博弈的情况。人工智能系统在协作、谈判、联盟等场景下仍然表现不佳。在这些博弈问题中,人工智能与自己进行对弈是远远不够的。假设我们拥有无限的时间和资源,通过自我博弈训练处的国际象棋智能体最终会学习到西西里防御。但是即使拥有无限的时间和资源,通过自我博弈训练的谈判智能体也无法学会说英语。如果我们想要在这些场景下取得成功,我们需要智能体能与人类交互,或收集人类的数据。

图 24:无媒介「外交」游戏中的基于 CFR 的搜索
多年来,「外交」游戏已经成为了多智能体研究领域的常用对比基准,它是一种 7 人博弈游戏,玩家之间同时需要进行合作和竞争,涉及同时行动的博弈。近年来,人工智能领域有多篇论文涉及「外交」游戏。在我们 ICLR 2021 上发表的研究「外交」游戏的论文中,我们使用与前文所述的方法相类似的技术,通过基于 CFR 的搜索和使用人类数据的监督学习首次实现了与人类相当的性能。这说明,我们在本次演讲中介绍的相关思想不仅仅局限于二元博弈或对抗博弈,它可以被扩展当更广阔的场景下。https://www.moshike.com/
结语

图 25:要点回顾
综上所述,Noam Brown 的研究工作主要关注对大规模环境下的均衡的高效计算,将搜索和学习技术泛化到单智能体环境和完美信息博弈中,最终开发适用于真实场景(混合协作、竞争、多智能体环境)下的人工智能技术。